
Pictured Left to Right: Velma, Scooby, Daphne, Shaggy, Fred.
Earlier this year, Jenny Ryan joined the cast of the ITV hit show The Chase as the fifth resident chaser. The Vixen will take her place among trivia’s rogues gallery alongside Mark “The Beast” Labbett, Shaun “The Dark Destroyer” Wallace, Anne “The Governess” Hegerty, and Paul “The Sinnerman” Sinha. Given Jenny’s trivia bona fides (QI elf, Only Connect series champ, University Challenge, Mastermind, and Fifteen-to-One alumna), it’s no surprise that she fit right in alongside the others, who between them have over 700 episodes of experience with crushing the hopes and dreams of unlucky contestants. But, after all those episodes, who among them is the best at their job? Who’s the one you would least want to meet at night in a dark alley of trivia? (Note: Given that Ryan has not had much time to accumulate data, we will ignore her for the purposes of this question.)
The chasers have two chances to catch contestants and eliminate them during the show. First, they can eliminate contestants individually during each contestant’s head-to-head round. Finally, they can eliminate the team as a whole by catching them during the final chase. Let’s look at each round individually and see what data we can get.
Head-to-Head Round
 During the head-to-head round, the contestant is tasked with getting multiple choice questions right, each correct answer allowing the contestant to take one step towards victory and earning money for the communal team bank. The chaser starts eight steps away from the finish. The contestant can choose to start either four, five, or six steps away from the finish (and thus starting with either a four, three, or two step head start on the Chaser), with the further starting locations worth more money. The Chaser and the contestant are asked the same questions, with each right answer bringing them closer to the finish line. If the contestant manages to stay ahead of the Chaser and reach the finish line, they put their earned cash into the communal bank, and earn a spot in the Final Chase at the end of the show. If the Chaser catches up to them before that happens, they don’t earn the money and are eliminated.
During the head-to-head round, the contestant is tasked with getting multiple choice questions right, each correct answer allowing the contestant to take one step towards victory and earning money for the communal team bank. The chaser starts eight steps away from the finish. The contestant can choose to start either four, five, or six steps away from the finish (and thus starting with either a four, three, or two step head start on the Chaser), with the further starting locations worth more money. The Chaser and the contestant are asked the same questions, with each right answer bringing them closer to the finish line. If the contestant manages to stay ahead of the Chaser and reach the finish line, they put their earned cash into the communal bank, and earn a spot in the Final Chase at the end of the show. If the Chaser catches up to them before that happens, they don’t earn the money and are eliminated.
It is tough to get an accurate read on the Chaser’s abilities from the data that we have in this round. We are relying on the results provided by the Chase Wikia, which only gives a one-line summary of how each episode finished. It would be great if we could watch all 707 episodes from the first eight seasons of the show and keep detailed records of the Chaser’s correct answer rate, but that may be a project for when somebody finally invents the 28-hour day. Still, we do have a record of how often each Chaser catches a contestant in this round. Can we do anything with that?
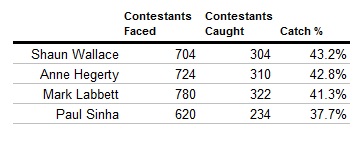
Before we put too much stock in these numbers, I do want to share my reservations about it. First, we do not have the data of how many contestants opted to start with a two, three, or four step head start. We can assume that each chaser gets about the same amount of contestants to step closer or further away, but it introduces a small element of imprecision we can’t address.
Another issue that muddies the water is that some contestants are uncatchable. If a contestant answers every question correctly (or answers incorrectly a fewer amount of times than their head start), then the performance of the Chaser is moot. It will always be chalked up as a loss. It doesn’t seem right that there are times that a Chaser could answer every question correctly or every question incorrectly and have it look the same either way in the data.
Finally, the bigger issue is that these numbers are so close as not to be statistically significant. Even though each Chaser has faced down between 600 and 800 contestants each, that’s still too small of a sample size to say that these numbers are definitive. The margin of error of each of these numbers at a 95% confidence interval is around 3.5% percent, as illustrated in this chart.
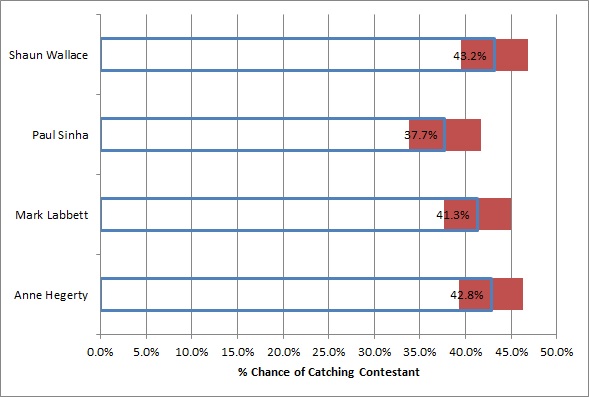
In this graph, we’ve highlighted the margin of error in red, representing where we think each Chaser’s true value could fall within a 95% certainty. You can see that even Paul’s low mark could theoretically still be the highest among the four.
So it’s clear that this analysis isn’t the best determination of Chaser performance. Can we do better in the Final Chase?
Final Chase
Pictured Left to Right: Ginger, Baby, Scary, Sporty, Posh
After every contestant has had a chance to play head-to-head against the Chaser, those who survive are brought back to try and win the communal bank. The team is given 2 minutes to answer as many questions as they can. The Chaser then gets another two minutes to try to match the score set by the contestants. If they do that, then it’s game over for the team. If the Chaser falls short, then the surviving team members split the bank. To even the playing field, the contestants are given two major advantages. Firstly, they earn a head start equal to the number of surviving contestants. Secondly, anytime that the Chaser misses a question during their turn, the clock is stopped and the contestants get a chance to answer it themselves. If they get the question correct, they push the Chaser back one step.
The data we have for this round is of a much higher quality. We know how many contestants the team has left and how well they scored during their two minutes. We also have the Chaser’s final score, and how long the Chaser took to catch the team if the Chaser won. What we’d like to do is use the Chaser’s score as the performance metric in this round, but we’ll need to do a few things first to take care of the variable conditions of this round.
 The most obvious place to start is by normalizing the amount of time each Chaser has to answer questions. Since the game is over as soon as the Chaser meets the score set by the contestants, we need to figure out what the Chaser would have scored had they had their full two minutes. That’s simple enough: We will give them credit for the missing time by assuming that they will continue to answer questions at the same rate. Thus, if a Chaser catches a team with a score of 15 with 30 seconds left, we will treat that as a score of 20. If the Chaser fails to catch the contestants, their score will not change, as they used the entire two minutes.
The most obvious place to start is by normalizing the amount of time each Chaser has to answer questions. Since the game is over as soon as the Chaser meets the score set by the contestants, we need to figure out what the Chaser would have scored had they had their full two minutes. That’s simple enough: We will give them credit for the missing time by assuming that they will continue to answer questions at the same rate. Thus, if a Chaser catches a team with a score of 15 with 30 seconds left, we will treat that as a score of 20. If the Chaser fails to catch the contestants, their score will not change, as they used the entire two minutes.
Now, there are a couple of issues with treating the scores this way. If a Chaser has to chase down a small score, it’s possible that they might take a couple of seconds extra to think about each question before answering. On the flip side, if they have to chase down a large score, they may rush and become prone to more mistakes. Also, (and I have no proof of this except my own anecdotal experience of watching the show) I feel that the host, Bradley Walsh, will speed up his reading of the questions if time is winding down and the Chaser is close to the target. While these are things we need to be aware of, I still feel comfortable about normalizing the scores in this way.
Pictured Left to Right: Niall, Liam, Harry, Louis, Zayn
The other thing we need to control for is the number of opponents that the Chaser is facing. Since the contestants get offered any questions that the Chaser misses, and their right answers are deducted from the Chaser’s score, the number of contestants left on the team has a direct impact on the Chaser’s final score. Analyzing the Chaser’s scores as a function of team size tells us that a two or three player team will earn around one more pushback than a one player team, while a full four player team earns around 1.5 pushbacks more than the single player. If the Chaser faces a multi-person team, we will give them credit for these extra pushbacks so the data is normalized to a Chaser facing a single player.
Now that we’ve eliminated all variables outside the control of the Chaser, here’s each Chaser’s average performance.
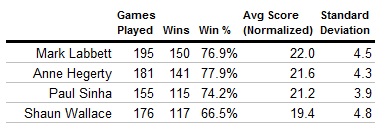
Mark, Anne, and Paul are all very close, but Shaun ends up averaging almost 2 questions less. This is borne out by using each chaser’s raw winning %: Mark, Anne, and Paul win about three-quarters of the time, while Shaun’s victory rate is only two-thirds.
This data does not suffer from the issues of the data from the head-to-head round. This data is a metric of raw performance on the part of the Chasers; we have eliminated any effects the contestants have on this score. It is also significant to a 95% confidence level. The margin of error on these numbers is between 0.6 and 0.7 of a question for each Chaser, which means that while we can’t say that Mark, Anne or Paul are better than one another, they all have performed better than Shaun.
Extrapolation
There’s something else that we can do with this data that’s pretty cool. To illustrate this, let’s take a look at a graph of the frequency of Mark’s normalized scores, rounded to the nearest whole number.
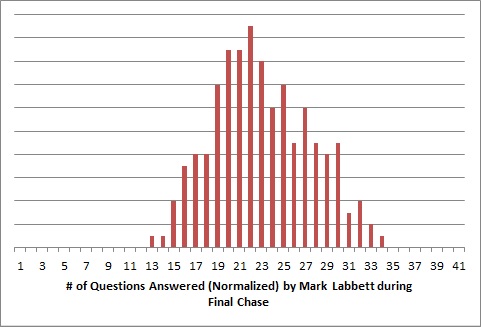
Say, that kinda looks like a bell curve, doesn’t it? Doing some normality testing on the data bears this hypothesis out; this data likely conforms to a normal distribution. The other Chasers’ data has the same feature. Therefore, since we know each Chasers’ average performance and standard deviation during the Final Chase, we can extrapolate upon this data and determine the odds of a Chaser beating any given score by fitting a normal distribution to each Chaser’s average score and standard deviation.
For example, let’s assume that a full team of 4 sets a score of 17 during their final chase. Not too shabby, right? What’s the likelihood that each Chaser will chase down that score?
Since our averages are normalized for a 1 person team, and this example uses a 4 person team, we will add 1.5 to their final score to represent the greater number of pushbacks that the team will score. So, the Chaser will have to score at least 18.5 points in order to catch the team. What is the team’s chance of victory against each Chaser?
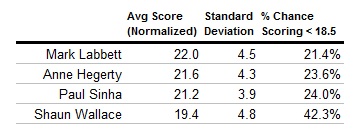
Here you can see just how much an effect that two question difference between Shaun and the other three has. Facing Paul, Anne, or Mark, the team has less than a 1 in 4 chance of victory. Up against Shaun, the team will run out winners 42% of the time.
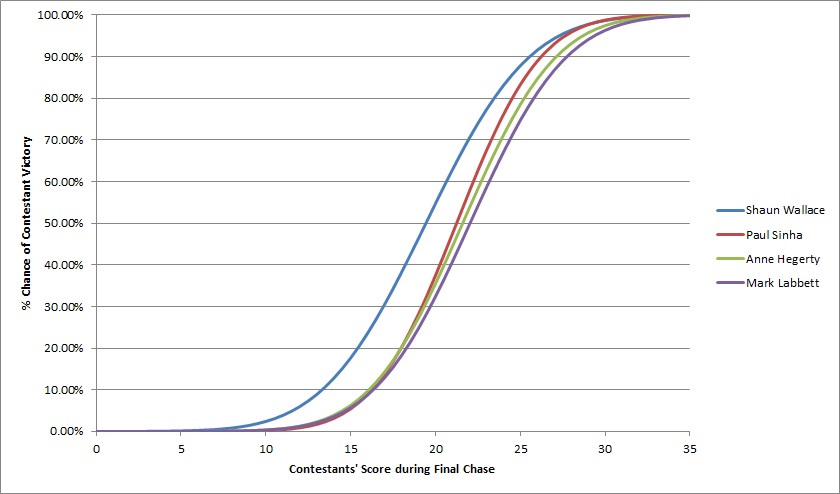
Here’s the full graph that shows the chance that a team will beat each Chaser based on their final score (before pushbacks).
Pictured Left to Right: Wasp, Hulk, Iron Man, Thor, Ant-Man
So who is the best Chaser? With the data we have right now, it’s hard to tell. I’d be inclined to call it a dead heat between Mark and Anne, with Paul just a nose behind them, and Shaun a bit further back. Despite this gap, I want to stress that Shaun is still an formidable opponent, and if the contestants facing him are expecting an easy game, they’re going to be disappointed. Time will tell how Jenny will fit into this group, but given her quizzing pedigree I expect her to do just as well as the other four regulars.
I think the Beast is the strongest. Anne may be further ahead on the winning percentage, the amount of times the Beast has versed a big score is ridiculous! Right after the Beast beated the score of 26 (iconic historical chase) the Governess versed a mere score of 8. And the Beast has a fast speed as well, probably unmatched globally.
Have you noticed the Beast always comes out with the biggest minus offers to contestants. Which they are usually reluctant to take and hence have less chance making it to the final chase it
The smartest chaser is ties between Mark & Anne.
I think the smartest chaser is Anne because look at the game percentage mark has played more I say Anne is the best by long shot
On the world stage however. Anne is credited as the most successful.
As statistics go, you can’t go by the table of win % as Mark Labbett has faced 3 scores of 26 and 1 score of 28 while Anne has only faced one score of 26 and no scores of 27+ So I’d tend to agree and say Mark is probably the best chaser
I have watched all 707 episodes from the first eight seasons of the show, and all 746 episodes since then – and have pretty much collected all the data that was broadcast. So please get in touch if you’d like to use it for further analyses.